GAS UrlFetchApp()のタイムアウト調査 - AIに何もかも教えてもらう今
世は生成AIが全てを動かす時代、果たしてこんな時代にテックブログを書く意味があるのか? 生成AIは言葉の壁すら存在しない、英語どころか聞いたことのない言葉で学んだ知識を、日本語で返してくれる。そんな時代に誰がググってくるのか?
そんな思いの中で、小さなことだがかろうじて生成AIが正常に判断出来ないことがあったので、書き残しておこうと思う。 Google Apps Script (GAS) の UrlFetchApp() のタイムアウトについての調査。
短く結論
Workspace契約のないGASは知りません、たぶん1分やと思いますが自分でしらべて下さい。
ここから本題
問題は UrlFetchApp() が6分でタイムアウトするというシンプルな現象から始まりました、順を追って試したことを示す。
単純に生成AIに聞く
UrlFetchApp()のタイムアウトは何分ですか?
これだけで最近のChatは勝手にタイムアウトを伸ばすにはどうすれば良いかを答えてくれます。timeout: 100 とかをパラメータで渡せば良いと返してきますが嘘です(コードは面倒なので書きません、見たいんなら自分で生成AIに聞いて下さい)。
これから悪い点を書くのですが、良かった点を逆に書くと、サーバー側でタイムアウトしてんじゃないのというクソリプみたいな返答はしなかったです。Claude-sanは結構おしゃべりしているので、筆者の属性を理解しているかもしれないですが、Gemini-sanとは最近話始めたばかりです。なんでこいつはそれぐらい調べてるって推測出来たんだろうか。
Claude と Geminiに聞きましたが、ほぼ同じコードを用意してくれました。ただ、後述しましたこのコードはまず通らないだろうなと直感しました。なので公式のリファレンスを先にググって調べました。案の定 timeout のようなパラメータはリファレンス上に存在しません。
せっかくなのでAIを詰めます。
Gemini-san はとぼける
まず、リファレンスをポイントしてくれと聞きました、正直にリンクくれました。リファレンスの中身もちゃんと理解して説明してくれました、timeoutが設定値として存在しない自己矛盾も含めて。じゃあ裏パラメータなのこれ?ときつめに言うととぼけた解答をしました。もう良いのでそこで会話終了
Claude-san は自分自身にも厳しい
ClaudeもGeminiとほぼ似た感じではあり、リファレンスに書いてないよと問い詰めたら、Googleのforumとかを引っ張り出してきて timeout を実装してくれと言うような要望が見つかりました、ということは今の時点で timeout は実装されてないかもしれません となんとも控えめな解答で情報を補足してくれました。これはやっぱすごいですね、さすが Claude
人間にとって簡単な問題でも今のところAIには難しいことも(稀に)ある
直感的に timeout: で伸ばせないのは私はすぐに直感で分かります。GASのような利用者人口が多いプラットフォームで、馬鹿みたいに長いHttpリクエスト投げられるの、俺がプラットフォーム側の人間だったら嫌だなーと考えます。じゃあタイムアウトは固定で変更出来ない、出来るとしても短縮のみ、あえて短縮したい人は(今考えるといるかもしれない)いねーだろと言うことで実装しないと思います。
こういう人間くさい心の醜さ
- ただでリソース喰われるの嫌
- どうせ誰も気にしないパラメータ実装するの嫌
という気持ちはある程度経験ある人間ならわかるが、生成AIの心は未だ我々のように濁っていない、だから逆に timeout: ってパラメータがあると推測する、ある意味常識的で、誰でも思いつくような解答をだす。
ただ、この濁った心もAIが持つようになるのは時間の問題です。この程度の知識でAIに対して人間がイキれるのも1年ももたないでしょう。
Claude-san と一緒に検証してみる
筆者の性分ですが、自分の目以外を信じません。99%確信していても自分で見たもの以外意味がありません、だから試します。
完全に試したいので 6分間何もレスポンス返さない、公開されたWebサーバが必要です。だるいですね。
これをそのまま Claude-san に聞きます。そうすると
httpbin.org
というサイトを教えてくれました、URLパスで delayを設定出来ます。素晴らしい、GAS側のコードも書いてもらいましたが、どうやら delay は10秒以上設定はできないようです、これはリファレンス調べました。
楽にDelayだけかけられるWebサーバを公開したい
ngrokというツールが昔存在しました、今もかな?これはローカルで動いているWebサーバを世界に晒すようなものなので、企業内で使うのはほぼNGなはずです。なんで自分のPCでやるかにはなると思いますが、どうせなら新しいの使いたいなら ngrok の変わり教えて でも良いんですが 自前のWebアプリを手っ取り早くインターネット公開する方法を教えて と聞くだけで良かったはずです。
候補はいくつかありましたが Serveo: expose local servers to the internet using SSH を教えてくれました。サイトいればすぐ分かりますが、 sshでリモートフォワードすれば良いだけです。こちらも会社のセキュリティーポリシー的にやって良いかは分かりません、私は自分のPC&ネットワークでやりました。 コマンド打つと、ホスト部分がランダムなURLが表示されます。そこを叩けばいいだけ。
コーディングとかもやってもらう
自分は copilot agent を使ってますが、何使ってもいいです。これぐらいの機能を今の生成AIが作れないことはあり得ません、どれも賢いです。Webサーバ側を作ってもらいましたが、かってに httpbin のようにパスに /delay/ で遅延時間をコントロール出来るように作ってくれました。
GASのコードはGeminiに最初に書いてもらったコードをURLだけ弄って設定しました。
結果は冒頭に書いたとおりです。6分でした、設定変更はパラメータでは出来ないですが、timeout が存在してもリクエスト時にエラーにはなりません。
ただ6分まって結果見るだけというアホみたいな作業なので、超久しぶりにウマ娘をやってました、おまかせ育成で。なんか目覚ましガンガン使われてるし、アーモンドアイ強すぎワロタ。
収穫
- httpbin という素晴らしいツール
- serveo というまあまあ便利なツール
- 人間はいずれ追い抜かれるが、このエントリーを学習で拾ってくれれば、ちょっとでも我々エンジニアは楽になるかも?まるでAIに使われているようではあるが
- おまかせ育成という素晴らしい実装
適切な方法でBigQueryスケジュールドクエリを実行する

BigQuery(BQ)のスケジュールドクエリは、普通に設定すると設定したユーザー、つまり人の権限で実行されます。 これを読んでる人は何が問題かわかっているはずで、退職時にそのユーザーアカウントが消滅すると動かなくなる、だけでは済まずに設定自体が消滅します。それを避けたいのでサービスアカウント(SA)で実行したい、ただそれだけの話だけど間違った手順が広まってしまっている。
まず最初に、SAの鍵は不要です。SAでスケジュールドをやるには鍵が必須かのような認識は、今すぐ捨ててください。
参考にすべきところ
https://cloud.google.com/bigquery/docs/scheduling-queries?hl=ja#using_a_service_account
Googleの公式をしっかり読むのが結局の近道です。信頼に足る情報源としてはここが一番
コンソールから設定する
DevelopersConsole(DC)から設定する。これは時期はわからないが、比較的最近の機能のはずなので、古い記事だと直接APIを叩くしかないようにも見えますが、今は一応DCから設定はできます。
そのまえに、誰が、何をするかをちゃんと把握する
通常のスケジュールドクエリは、おおよそ下記の手順で作っているはずです。
- AさんがSQLを作成する (実際に流して結果を確認する)
- そのままスケジュールドクエリとして登録する
- スケジュールドクエリはAさんの権限で実行される
これをSAで実行する場合
- AさんがSQLを作成する
- スケジュールドクエリとして登録するときに、実行ユーザーとしてSAを指定する
- スケジュールドクエリはSAの権限で実行される
最後のスケジュールドクエリの実行はBQリソース=テーブルやデータセットに対するアクセス権限は、AさんとSAへの認可を同じものが必要。
もう一つ、SAで実行するために、スケジュールドクエリを設定するときに、SAを使う権限というものがAさんに必要となります。
また、なぜかGoogle管轄のプリセットSAに対して iam.serviceAccounts.getAccessToken が足らないとメッセージが出ることがあります。なぜ必要か説明できなし、100%発生するわけでもないです*1が、従いましょう。
- SAに対してBQリソースへの認可
- 設定を行う人に対して 対象SAを使う認可 (Web-UIから設定したいならば、プロジェクト内のSAを列挙する認可)
- 原理は不明だが、プリセットのSAに対して
iam.serviceAccounts.getAccessToken
DCでやってみる
まず、Aさんの権限で実行してみる。参考までに下記を付与したとする。ちなみに書き込み権限は下記にはないので、調整してください。
bigquery.jobs.create bigquery.jobs.list bigquery.routines.get bigquery.routines.list bigquery.savedqueries.create bigquery.savedqueries.delete bigquery.savedqueries.get bigquery.savedqueries.list bigquery.savedqueries.update bigquery.transfers.get bigquery.datasets.get bigquery.tables.get bigquery.tables.getData bigquery.tables.list bigquery.transfers.get bigquery.transfers.update resourcemanager.projects.get
この状態でAさん自身の実行でスケジュールドクエリを定義できることを確認しておく。
次にSAを使って同じスケジュールドクエリを定義する。SAを作成して、上記Aさんと同じBQリソースに対する権限を付与する。 そこから、AさんにはSAを列挙&使う権限が存在しないため、付与する必要がある。

プロジェクトの規模にもよるが、一番安全に倒すならば、Aさんに与えるプロジェクトレベルの認可としては、SAの取得とリストのみに絞り、SAを使う認可はSA自体の権限(AWSでいうリソースポリシー)として付与するのがよい。具体的にはSAを列挙する専用ロール(SA列挙ロールと名付ける)をつくって、その中身を下記としプロジェクトでAさんに付与
iam.serviceAccounts.get iam.serviceAccounts.list
さらにSA自身の認可(このサービス アカウントにアクセスできるプリンシパル)としてAさんにServce Account User: roles/iam.serviceAccountUser のロールを付与すればOK
これでスケジュールドクエリの設定は成功する。が、設定は成功しても実行時にまれに下記のメッセージでコケることがある。
P4 service account needs iam.serviceAccounts.getAccessToken permission. Running the following command may resolve this error: gcloud iam service-accounts add-iam-policy-binding <SA-user-email> --member='serviceAccount:service-<project-id>@gcp-sa-bigquerydatatransfer.iam.gserviceaccount.com' --role='roles/iam.serviceAccountTokenCreator'
これが発生したりしなかったりで、原因はわからないが、素直に SAのポリシーに service-<project-id>@gcp-sa-bigquerydatatransfer.iam.gserviceaccount.com に対して iam.serviceAccounts.getAccessToken を付与する。
bqコマンドでやってみる
bq コマンドでやる場合ならば、SA列挙ロールは付与していなくてもOKで、SA自身の認可だけあればよい。

bq コマンドで設定する。下記はすでに定義済みのスケジュールドクエリ(転送設定)の実行ユーザーだけ差し替える方法。詳しくは公式より
https://cloud.google.com/bigquery/docs/scheduling-queries?hl=ja#bq_3
bq update \ --update_credentials \ --service_account_name=<SAのメアド> \ --transfer_config \ <スケジュールド・転送設定のリソース名>
転送設定のリソース名は
bq ls --transfer_config --transfer_location=us
とかで確認できる。ここで再度まとめておくと、AさんがSAで実行するように設定するので、AさんがSAを利用する権限が必要となる。
SA鍵を発行して、SA鍵で認証して、SA自身になりきり、SA自身をスケジュールドクエリ実行ユーザーとすることはできるが、そんなことしなくていいし、危険だから今すぐやめたほうがいい。AさんがSAを使える、もっと突っ込むと iam.serviceAccounts.actAs があればよい。で、このiam.serviceAccounts.actAs をプロジェクトレベルで振ってしまうと危ないので、SAのポリシーバインディングで付与する。
落ち穂拾い
DCから既存のスケジュールドをSA実行に切り替えたい
クエリのスケジューリング | BigQuery | Google Cloud
DCからはできないと書かれていますが、こことは別の方法でできます。BQコマンドが嫌な人はこちらで


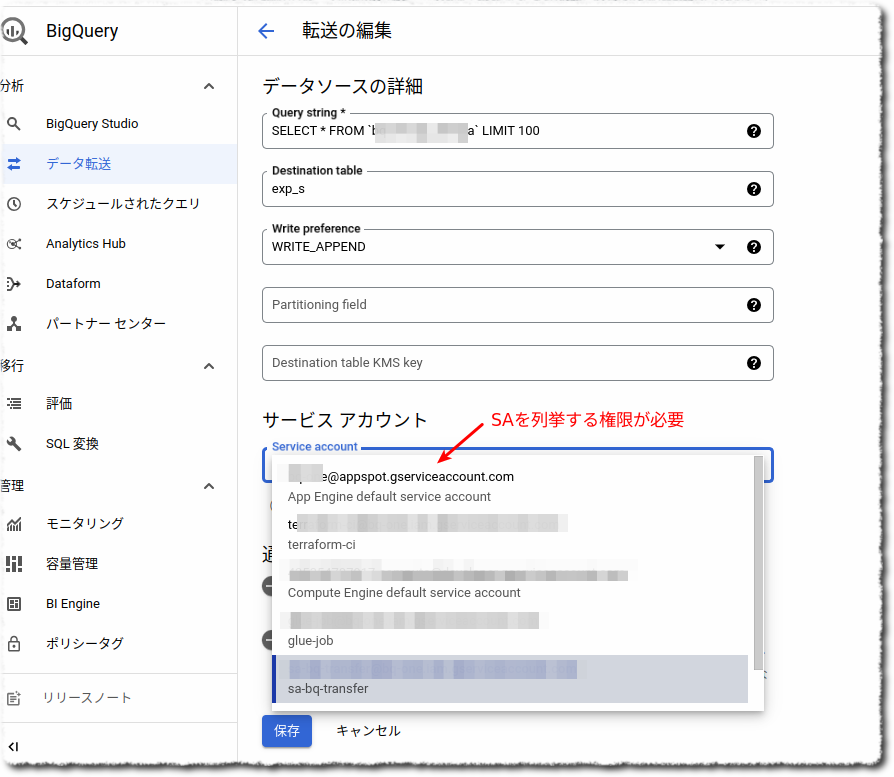
他のプロジェクトで作ったSAで実行したい
結論から言うと、できるが、おすすめしない。
まず最初に、SAを作成したプロジェクトと、リソースがあるプロジェクトは同一である必要はない。AWSはアカウントごとに認証装置があるからこそクロスアカウントとかいう仕組みが必要だが、GCPはプロジェクト単位で認証は発生していない。だからクロスプロジェクトしていても、認可さえ与えれば問題ない。
が、SAをプロジェクト跨ぎで特定プロジェクトのリソースに縛り付ける(e.g. GCEのSAや、今回のスケジュールドクエリのSA)に使うことは、GCPのIAMによる 組織ポリシーにより禁止されている、デフォルトで。これ、組織ポリシーと名前はついているが、プロジェクトレベルでのポリシーとして動いている constraints/iam.disableCrossProjectServiceAccountUsage 、詳しく知りたい人は自分で調べてください、スクリーンショットだけ貼っておく。

ここまで読んでいる人なら大丈夫だと思うが、念の為
- SAと、スケジュールドを仕込むプロジェクトは同一
- ジョブからアクセスするBQリソース(dataset, table ...) はプロジェクトまたいでいてOK
*1:筆者の環境では一度発生すると2度目以降は不要でした。プロジェクトによってはそもそも発生しない場合もあり。
AWS Lambdaが何故か何回もinvokeされてる、しかも成功してるのに
AWS Lambdaで久々にハマったので、理解を深めて残しておこうと思う。 もうGAからずいぶん経っているが、自分が初期のLambdaをよくわかってない、ということがわかった。
全部すっ飛ばして結論
- Lambdaを同期実行 + AWS SDK/CLI などで単体実行するときは、Client側のタイムアウト設定を、Lambda側のタイムアウトよりも長くする
- Boto3(Python)の場合は、1分以上Lambdaの実行にかかる場合は、これを守らないと3回ぐらいLambdaが勝手にInvokeされる
概論・今となっては特殊な動かし方の説明
Lambdaは基本なにか別サービスと連携して使うものです。しかし単体でも実行させることは可能です。(どこかのテックブログにはできないと書いてましたがこれは嘘です。)
今回の目的は、この完全に単体でLambdaを実行することです。結構レアケースだと思いますが、もはや世の中の情報が溢れかえっているのでこのレアケースを正確に示すためだけに外堀の解説を超雑にします。
同期・非同期実行
想像ですが、初期のLambdaは同期実行しかできなかったはず。同期とは、想像通り呼び出し後、Lambdaが完走するまで待ちます。結果もすぐに取り出せます。
対して非同期は文字取り、呼び出しが成功した時点で、一旦成功が呼び出し側に返ります。
アナタの言いたいことわかります、「じゃあ、全部非同期でよくね?」
しかし、おそらくアナタの考える非同期とちょっと違います。「Invokeすると Invoke-Idが帰ってくるんでしょ?それをポーリングすればいいんでしょ?」と思って調べるとそんなAPIないです
Lambdaの非同期実行の結果を取得する場合、別のサービスに投げる・失敗時向けとしてはDLQに投げる設定が可能で、その結果を能動的に 取得する必要があります。
サービス連携と同期実行
一番多いパターンは API Gateway + Lambda のパターンだと思いますが、この場合は基本、同期実行。非同期もできるはずですが、書きたいことから外れるので端折る。
API Gateway がリクエストを受けて、Lambdaを叩いてすぐに結果がほしいから、なんとなく同期で納得するとおもう。Httpリクエストで何分も待たせることないしね。
同期実行で動いているパターンでも、サービス連携している場合がほとんど。ここで言いたいのは、同期実行 ≠ 単体実行 ということ
単体・同期実行やりたい理由
「そもそもなんでお前、単体実行したいの?」については
権限をギンギンに絞りたい場所・リソースにアクセスする必要があるのだが、処理は超簡単でシュッと結果だけがほしい
という、今となってはレアケースとなってしまった、初期のLambdaの使い方にマッチすることがあったから。
「まあ、そのケースでも EventBridgeとかでCron実行するでしょ?」となるので、ホンマに単体実行なんてレアやとおもいますが、もっと正確に言うと、定期実行するジョブの一つの工程で、上記のケースが発生したため使った。
本題・問題発生パターン
単体・同期実行で発生しうる問題は
呼び出しがタイムアウトした場合、boto(core)の機能によりリトライされて何回もinvokeされる
詳しく説明
同期実行の場合、Lambdaのinvokeは、Lambdaが実行完了 or 異常終了するまで処理まちします。この処理まちというのが、一般的なhttpsリクエストと同じです。 Lambda側で最大実行時間(タイムアウト)は設定できます、が一般的なhttpsリクエストと同じなので、client側がちゃんとLambda側のタイムアウトまで待ってくれるように仕込まないと、ちょっと重い処理ならclientが早々にあきらめて、永遠に成功しない。
awscli / boto3 で lambda invoke を叩いた場合、このclient側のタイムアウトは、botoの標準設定となります。ちなみにbotoは60秒です。ちなみにbotoは自動リトライ機能もついています。デフォルト3回だったはず
実験
labmda関数は timeoutと名付けて、下記コード。サンプルにsleep足しただけ。
これで、Lambda側の timeoutは 2分にしておく。
import json import time def lambda_handler(event, context): time.sleep(90) return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda!') }
awscliで叩いてみる。全部垂れ流すように --debug 付きにしといたほうがいい。
$ aws lambda invoke --function-name timeout result.txt --debug 2022-04-23 17:33:41,590 - MainThread - botocore.retries.standard - DEBUG - Max attempts of 3 reached. 2022-04-23 17:33:41,590 - MainThread - botocore.retries.standard - DEBUG - Not retrying request. 2022-04-23 17:33:41,590 - MainThread - awscli.clidriver - DEBUG - Exception caught in main() Traceback (most recent call last): ... socket.timeout: The read operation timed out During handling of the above exception, another exception occurred: Traceback (most recent call last): ... urllib3.exceptions.ReadTimeoutError: AWSHTTPSConnectionPool(host='lambda.us-west-2.amazonaws.com', port=443): Read timed out. (read timeout=60)
ご覧の通り、read timeout = 60で、client側がLambdaをまちきれずに諦めている、それにリトライも3回やってる。
Lambda側のメトリックスだけみると、「成功してるのになんで3回も叩いてるの?アホなの?」となる。
awscliでも timeoutを指定できるので、今度は2分 client側も待つようにする。
あとから考えると aws cliを使うのはやめて、認証情報をつけることさえできれば、素直にcurlなり普通のhttp clientでやったほうがええです。
$ aws lambda invoke --function-name timeout result.txt --cli-read-timeout 120 --debug
...
2022-04-23 17:44:23,495 - MainThread - awscli.formatter - DEBUG - RequestId: ....
{
"StatusCode": 200,
"ExecutedVersion": "$LATEST"
}
今度は成功する。
対策boto3の場合
import boto3 from botocore.config import Config conf = config(read_timeout=120, retries={'max_attempts': 0}) client = boto3.client("lambda", config=conf) client.invoke(...)
retryも黙らせたほうがいい。
令和4年の Desktop Linux
Linuxをクライアントとして使い始めて2年ぐらいたった。ubuntu 22.04 LTSが出る前だが、日記的に書いとく。

結局どやねん?
ubuntu 20.04 LTS @ ThinkPad X1 6gen を使っているが、生活はできる。
できるが、いろいろ面倒なのは違いない。
じゃあ、Macなら面倒無いのか?と言われるとそうでもないかもしれないが、当たり前だが情報量が圧倒的に少ないので、それなりに自己解決していけないと苦しいな。
自分が結構困ったときのメモ、(解決方法は書かないので、期待しない)
ハイバネーション
解決方法はググれば出てくるので自分で調べてください。だが、「未だにハイバネーションシュッとできないのかよ!」
注意は、Deep Sleepという完全にディスクに逃がしてバッテリー消費を抑える、普通の人が知ってるハイバネーションを実現するには、ハードウェア側でも対応が必要なようで、ワイのハードでもファームの更新が必要だった。ファームの最新情報も Ubuntu Software (アップデートのランチャーみたいなの) に出てくるので、ファーム更新自体は楽だが。
wayland or x.org
これも未だに決着がついてないみたいだ。何年やってんだよ
いろいろ改善が進んでそうだが、GPU積んでるならドライバの関係でx.orgらしい。私は Fractional Scaling (高解像度ディスプレイを、老眼仕様にするやつ) で謎のノイズが出たのでwaylandにしたが、別の問題がいろいろ出てきた。
wayland とかなんやねん?
長い話になるから、端折って書くと、Linux等はCLI至上主義だから、GUIなんておまけで超ファットな仕組みでGUI(ウインドウマネジャー)を実現してた。サーバーはそれでいいが、デスクトップでいつまでもCLI至上主義ってどうなん?いい加減古いやり方辞めへん?となって waylandが出たが、X 想定で書かれているアプリケーションは当然動かないよね。「めんどくせー wayland対応なんてやらねーよ」というアプリ開発者も結構いる、いたようで、主要なアプリはwaylandでも動くが、マイナーなのは、、、という状態。
キーボードリマップツール
人によるが、俺はこれがないと生きていけない。x.orgで動いているものが waylandで動くとは限らない。おれは xremap を使ってる、ありがたや。
スクリーンショット
skitch と同じでええんやが、これがなかなかない。
shutter が機能的に最強だが、waylandで動かない。 flameshotはかなり近い操作感だが、日本語打てない。 ksnipも日本語打てない(直接ね、コピペはできる)。結局普通の標準機能でスクリーンショット撮って、shutter で編集が俺にはあってる。
Fraction Scalingしてもブラウザ画面汚い
他のOSみたいにHiDPIなディスプレイを150%,200%とかにスケールしても、キレイに表示されない。gnomeで出来ているであろう設定画面自体はパッキパキのフォントで描画されてるので、やり方次第なんだろうけど、これは悲しい。俺はしょぼいPCにLinux入れて「軽いぜ〜ウェーイ」やりたいのとちゃうねん!ゴリゴリの最強スペックをLinuxで使いたいんや!4Kモニタを200%で使って、えもいわれぬ美しさを求めてるんや!おれの 4K 200%のスクリーンショットがこんな感じ

正直よーわからんが、これでもwaylandのほうが x.orgよりはキレイらしいで。時間が解決するのかな?
snap..
詳しくはしらんが、xxxenvみたいな特定アプリごとにランタイムを使い分けるような類のもの、Dockerよりももうちょっとゆるいのかな。俺はインフラ屋だったから、この手のシステム汚さない系は「これ、ええやん!」と最初は思ったが、それこそスクリーンショットやら、クリップボードツールやらのように、単体解決するようなアプリならそれでええんですが、firefoxの拡張機能とか、emacsとか他のアプリとプロセス間通信するやつは結構難儀になる。 firefoxは 22.04(21ぐらいから?) snapになってしまったらしい、うーん。
いいところ
それなりに軽い・余計な心配ない
ほとんどの人が、結局クリーンインストールだと気に入らないはずなので、いろいろいじる。だから変なプロセスがリソース食ってるということはまずない。初期構築さえ乗り越えれば、そんなに不満なくやりたいとに集中できる。
Docker
Linuxは今の所 Docker Desktopがないので、税金払わないという点はええのだが、rootless dockerとか、user mappingずらしとかいろいろいじってしまうと野生のdocker-compose拾ってきて upで動かないというので何度もハマってる。Dockerは余計なことしないで、サーバーと同じ動かし方でええと思います/それができるのがLinuxの良さ。
結論、どのOSもたいして進化してないね
デバイスドライバ問題は20年前から比べてだいぶマシにはなっているはずですが、テンション上がるような進化はなんにも起こってない。特にここ10年は
じゃあ、WinやMacはどやねん?やけど、どっちもここ10年は全然進化してないね。あえていうなら仮想化ぐらい? スマホ・小型デバイス向けが忙しいからもう、世界レベルでDesktop OSなんかはもうどうでもいいということか。
例外はvistaがLonghornとか言われてたときぐらいやわ、ワイの記憶によると。
Log Volume (GCP Cloud Logging) の料金が高杉なんだが

Google Cloud Logging が異常な請求額になったため、その原因と対策を説明する。請求レポートの Log Volume (Cloud Logging) がなんか高いなーと調べてる人は正解!ここです。
Loggingは結構使われる重要なコンポーネントにもかかわらず、優れたエントリが非常に少ない。そんな中でも見るに値するものは下記しっかり解説されていると思います。
上記で大部分の知識は得られるとおもうので、金額が高くなった理由を書く。
原因と対策
- GCSのAPIアクセスログがデフォルトで
_Defaultにも Sink(シンクは日本人には意味かぶりするのでこう記載する)される - GCSをバリバリ触るなど、極端にAPIアクセスが多いプロジェクトの場合、30daysの保持期間はどうでもいいので、Sink対象を_Defaultから除外する
- GCSのログを別途保持したいのならば、ログバケット(
_Default)ではなく、GCSバケットなどにSinkする
仕組み
予備知識何もなしでは意味がわからないので、上記の参考エントリを見てもらうことを推奨しますが、玄人向けに雑に書く
ログバケット/ログストレージ
まずこれ、GCSのバケットとは違います。GCSの一覧には出てこない、Googleが管理管轄するやつなので、GCSバケツのようにユーザーには直接は見えない。
_Default と _Required の2つがデフォルトで存在し、お金かかるのは_Defaultの方。
ログエクスプローラで見えているのは、ログストレージの中だけ
まずログルーターを理解する。

ありとあらゆるログは、一旦 Cloud Logging APIに入る。ここまで金はかからないはず。
次にログバケットにSinkされる。ログエクスプローラでは、このログバケツの中のものだけが見えている。ここがダダじゃない、盲点。
Sink先は、GCS,Pub/Sub,BigQueryなど選べるが、これらへSinkしたものはログエクスプローラは関係ないし、Sinkすること自体には金かからず、GCSなどのストレージコストがかかる。
ログエクスプローラは _Defualt, _Required どっち見てるの?
両方見てる。自分はこれが理解できてなかった。そもそもLoggingは30日タダという昔の知識があった。それなのに「あれ、30日よりも前に辿れるけど、どういうこと?どこかにSink(ログバケットではなく、GCSとか)してたら勝手にそっちみてくれる?」と深く考えてなかったが、これは _Required 分が見えていたのだった。
コンソールいうとこんな感じ

請求の詳細にはなんと出る?
Log Volue (Cloud Logging) と出ている、SKU-ID: 143F-A1B0-E0BE 「あれ?Loggingは30日でしょ?なんでこんなに請求されるの?」 これを見ている人と同じ原因で俺も調べ始めた。
「もうちょっといい表現あるだろ」とは思うが、まあ間違っていないし、一言で説明するのは無理か。
30日の保持期間はこれとはほぼ関係なく、ログバケットに取り込んだ量を指します。課金対象の _Default に
で、悪いことにこのログバケットへのSinkが超高い $0.5/1GB
監視できるの?
結構丁寧にUIにも出ている、気づかんかったけど。

Monitoringに飛ぶリンクもついていて、それで加算でないかはわかる。このときのメトリックスはxxx Ingest とか書いてある。ユーザーから見たら ingestとは逆の感覚だな。
対策 _Default に特定イベントが飛ぶことをやめる
俺の場合は、GCSのイベントだった。まあ、AWSの感覚からしたら、GCSのイベントがデフォルトで全部取り込まれるのは 頭おかしい 文句は後でまとめて書くが。
_Default については、どれをSinkの対象とするかの設定ができるので、 GCSのイベントを除外する設定を入れたら料金は収まった。繰り返すけど、30日を縮めてもいみないからね。

NOTに追加するか、除外に指定するかはお好きなように

_Default への Sinkやめたら、 GCSへのSinkとかも失敗しない?
大丈夫、失敗しない。上で示した概要図みて。GCSなどログバケット以外へのSinkは _DefaultからのSinkではないから。
ダメ出し・文句
Cloud Logging は AWS CloudWatch Logsと大体同じで、AWSの感覚からすると(かつて、今は違う)「30日タダは太っ腹」に見えたが、GCSのログを全部デフォルトで取得する判断はないわ、ありえへん。だってAWSですら、ただ単にCloudTrailでS3にファイル吐き出すだけでも、デフォルト Offにしてるのに、さらに10倍以上も単価の高いCloudWatch Logsに全部打ち込むとか、正気の沙汰じゃない。
もちろん、ログストレージが高いのはわかる、ログエクスプローラやログからメトリックス作れるので高機能だ。だが、デフォルトで全部突っ組むのはありがた迷惑。
思惑としては、ログエクスプローラでなんもしなくてもGCSのログ見れまっせ!監査もバッチリアピールしたいんだろうし、アプリ開発者は自分の撒いたログがシュッと見れればええんやろ、だから邪魔くさいインフラ部分の説明は覆い隠したいんだろう。でもそこでユーザーへの説明端折っても、ユーザーの学習をスポイルしてもあんまいいことだとは思えんな、現にクレーム来るからわざわざ料金アラームのリンクつけてるんでしょ?
気づいたのは GCSだけだが、同じようにサービスAPIが大量にログを作るサービスは他にもあるだろうきっと。
俺が選挙に行く理由
選挙直前だが、なんとなく書きたくなったので書く。俺が選挙に行く理由、それは 祭りに参加したいから!
俺の今まで
俺と選挙
俺はいわゆるロスジェネ世代。俺が若者のときももちろん、「最近の若者の投票率ガー」と言われてたが、そんなの構わず、1回を除いてすべての選挙権は行使している。唯一投票できなかったのは、2週間ぐらい風邪で寝込んだことがあり、そのときだけは無理だった。皆勤賞の俺でもそういうときはある。ちなみに俺はどこかの党員でもないし、活動家でもない。
俺と親父
親父がよく言ってた。「誰に投票しても同じや!」「こいつは当選させないという投票なら行くわ!」。俺の知る分では、親父は一度も投票しなかったはず、もしも当選させない選挙があっても行かなかっただろう。俺が選挙に行くのはこれの反動かもしれない、だって俺のからだの70%は反骨精神でできているから。
俺の20代
20代は独身で、リア充ではなかった。別に政治に興味があったわけでもなかったが、暇つぶしに選挙に行ってたのかもしれない。もしも20代の俺がリア充だったらどうだろう?それでも多分選挙は行ってたと思う、だって俺はひねくれものだから。
俺と氷河期
バキバキの就職氷河期です。今ほど「政治がわるい」「あの人が戦犯」とは言われてなかったなあとおもう。俺自身は運良く生きのこれている、そのせいか政治を恨んだりとかの感情はなかった。ただ、同世代の苦しんでいる人に「根性がないだけ!自己責任だ」とは絶対に言えない、逆にそういうの聞くとまじでムカつく。
俺と妻と家庭
妻も「投票いかなきゃ」「どうせならこの人に入れる」と選挙には前のめりの人だ。結婚すると、子供ができると選挙どころじゃないこともあるだろうが、幸い俺は選挙に行きやすい環境にいる。期日前投票したこともあったな。
自分語りの理由
誰もが俺と同じような環境にいたわけではない。どうしても行けないことだってあるだろう。政治に興味ない人もいるだろう。一票なんて無駄と考えるひともいるだろう。それは構わないし尊重すべきだ、みんな事情があるし、俺と同じ環境でもない。外に晒す文書なんでこういうやつがこういうふうに感じた補足。
選挙は祭り?
投票所に行く、夜に選挙速報を見る、自分の入れた票とか支持政党とかの結果をみる。これだけで楽しい、祭りだエンタメだ。しかしただの祭りと違って、祭りのあとの日々にも影響する。
投票しないということ
投票は義務ではない、強制ではない。投票しないということは、世の中の他の人に委任したとも言えると思う。よくわからん自分が投票して、変な人が政治家になるぐらいなら他人に判断を委ねるというのもあるだろう。もしくは単にめんどくさいという人もいるだろうが、どちらによ悪いことだと思わない。
投票義務化という話もあるらしいが、あんまりいいことだとは思えない。一生政治に無関心という人生もあっていい、そういう人がいるほうがおもろい。
投票するということ
世の中に与える影響としては、誰かを支持したという1票になる。もしくは嫌いな候補者を当選させないための1票を対抗にいれたということになる。俺はこの意味よりも、自分自身に与える影響のほうが大事だとおもっている。
自分で投票のすること意味=決断を他人任せにしない
他人任せが嫌なら立候補しろやというのもあるが、まあ俺じゃ当選しないわ、ええ年した大人ならわかるやろ? ほぼ皆勤賞で投票してるが、政権が変わったときに自分はどこに入れたかとか、大体覚えてる。 「なんであのときあそこに入れたんだろう?」「俺の1票無駄だったな」「白票でも意味あるやろ」後悔することも、徒労感もいろいろあった。 でも俺は選挙に参加した。だから責任がある、成功も失敗も後悔も無力感も全部自分のことになる。だから次の選挙はどうしようと考えられる。
素人が口出すなだと?やだね
若いやつは政治に興味ないとか、自分のこととして考えられないだとか、ごちゃごちゃ言ってるのを見るが、若い頃の俺は大した考えもなく祭りだと思って選挙に行った。それで何がわるい?
マスコミに影響されて投票した、ポピュリストを見抜けずに投票した、圧勝するのにわざわざ投票した、どんな結果であれ参加しないと自分の経験にはならない。投票しないことは委任でもあり、その考えは尊重されるべきだが、どうしても当事者意識は薄れる。「俺以外の世間のバカどもがしょうもないやつに騙されて当選させた」、と政治が悪くなってきたら、あとから文句いうことができる、だって自分は参加していないのだから、全部他人のせいにできるから。
若いうちは政治なんかわからん、そのとおりだ。俺だってそうだった、ジジイになった今でも政治なんかようわからん。誰かの思惑に騙されてるのかもしれない。でも、あのときの判断は良かった・悪かったははっきり自分の中に残っている。そして次はこうすると考えるようになれた。それはテキトーだろうが投票してきたからだ断言していい。
もしも政治わからん若者が、だれかに扇動されてヤバそーなやつが当選しそうになっても構わん。少なくとも俺は阻止するために対抗に票いれる、次の選挙が仮にそんなことになっても自分で納得できるように選挙に行く、いつでも。
で、ホントに選挙は祭り?でいいの?
ええやろ。自分の選挙権をどう使おうが他人にとやかく言われる筋合い無い。ノリで選んで全然OK、選挙よりもおもろいことあるなら、そっち優先でもいい。ただひとこというと「選挙、結構おもろいで!」
バケットポリシーとCloudTrail Logの組み合わせ
今回書くことは、もうすでに手垢がついているので、なるべくさらっと書きます。
2022/02/01今更ですが更新 ACLやめればすべて解決!
【アップデート】S3でACLを無効化できるようになりました #reinvent | DevelopersIO
テーマはバケットポリシーとクロスアカウントアクセスです。本エントリでも少しだけ触れますが、原理はこちら
新機能サイコーな話なんですが、運用視点で書きます。

バケットポリシー発動条件
バケットポリシーを設定したら発動とかそんなしょうもない話ではない、バケツの所有者と・オブジェクトの所有者が一致しているときのみ発動します
これは頭に叩き込む、ここがブレるとわけがわからなくなる
挙動の確認
バケツの所有者がクロスアカウントアクセスによって書き換えられることはありません。よって、クロスアカウントアクセスの書き込みによってバケツの所有者は絶対に変わりません。しかしオブジェクト所有者はアップロードしたAWSアカウントののものになります。SS貼っときます。
これが 普通のオブジェクト バケツ=オブジェクト
 これが 問題のオブジェクト バケツ≠オブジェクト
これが 問題のオブジェクト バケツ≠オブジェクト

上記に書きましたが、バケツに対するAPI ListBucket(ListObjectではない、ここが怪しいひともググって)は通ります。aws s3 ls でオブジェクトの有無は見える。しかしGetObjectは通りません。上記のSSは一つのバケツに、普通のオブジェクトと所有者違いのオブジェクトを混ぜた。こんな状態でも普通のオブジェクトに対しては GetObjectは通る
- バケツ所有者とオブジェクト所有者が違うとバケットポリシーは効かない
- バケツ所有者とオブジェクト所有者が違っても、(バケットポリシーでListObjectがついてたら)
aws s3 lsは通る - 一つのバケツに、所有者同じ/所有者異なるオブジェクトが混在することはできる、その場合、所有者同じオブジェクトに関してはバケットポリシーは有効
クロスアカウントアクセスによる書き込みは、実はすべてのAWSアカウントで発生している
今回のテーマはこれです。クロスアカウントからの書き込みって、特殊なことに思えますが、実はほぼ全てのAWSアカウントで発生しています。
どこで? 確認できているところで、CloudTrailとELBのログ(他にもあるかも)
そもそもAWSが出すログってどう出してる?
CloudTrailのS3Exportをポチポチで作るとS3側にはバケットポリシーが書かれています。
CloudTrail の Amazon S3 バケットポリシー - AWS CloudTrail
自分のアカウントと異なる、AWS自身が直接管轄しているアカウントからの書き込みが発生します。つまりこれも クロスアカウントによる書き込みです なんにも考えずにクロスアカウントで書き込んでしまうと、そのバケツのオーナーも読めなくなってしまうので bucket-owner-full-control を必須にしています。ELBもバケットポリシーからみると、同じ挙動のはず。
何が困るの?
bucket-owner-full-control がついてるので、バケツ所有者(のアカウント)であれば問題ないです。が、ここでバケットポリシーによるクロスアカウントアクセスをしようとするとだめ。バケットポリシーはバケツ所有者とオブジェクト所有者が違うとバケットポリシーは効かない という鉄の掟があるから。
どうすればいい?
これからの人
です、設定方法は最初にポイントしたところを見てください。正直なところ、この設定をして損はしないと思うので、今後作製するS3バケットは一律この、オブジェクト所有者とバケツ所有者を一致させる設定をしておいて問題ないでしょう。
もうオブジェクトいっぱいある人
機能拡張により、ACLやめるですべて解決。ACL機能が削がれているので、オブジェクトのオーナーが誰とか一切関係ないので、既存オブジェクトも問題なしでした。
Linuxやったら chown すればいいですが、S3は所有者を変更するAPIは生えてません。ググるとこんなん出てきます。
ざっと見てみると、s3 sync で新たなバケツにコピーです。つまり、同一オブジェクトの所有者だけ変える方法は存在しない。
まとめ
| バケツ所有者とオブジェクト所有者が | bucket-owner-full-control | アクセス可能 |
|---|---|---|
| 同じ | ついてなくてもOK | バケットポリシー有効 |
| 違う | ついている | バケットポリシー無効+バケツ所有者は見える |
| 違う | ついてない | バケットポリシー無効+オブジェクトオーナーのみアクセス可能 |