AWSのWebサイトでは、DynamoDBの説明として
DynamoDB は高速な完全マネージド型 NoSQL データベースサービスで、任意の量のデータを格納、取得し、任意のレベルのリクエストトラフィックを処理できます。
と記載されています。NoSQL? KVS?
RDBとは違うことはよくわかっていても、どんなものか触って確かめてみますが、先にどんなものか簡単に書き起こします。
-KVSなのか?
KVSであることには間違いないですが、イメージしているKVSとはかなり違います。文字通りKeyとValueだけではなく、少し
SQLぽいことができるRangeIndexを作れる点がだだのKVSとは違います。また、expire機能も無いので、このままでmemchacedやredisの変わりとするのは工夫が必要です。
-スキーマレスなのか?
スキーマレスと言って良いと思います。もちろんKVSに当たるKeyの部分は必須ですが、グローバルセカンダリインデックス、ローカルセカンダリインデックスという、なにやら
RDBのインデックスに近いものは、Nullを許容しています。(正確にはNullを許容というより、そのアイテム(レコード)にはそのカラムがないということです)
-NoSQLなのか?
NoSQLです。
SQLのような複雑な問い合わせや、集計と言った機能を持ちません。しかし、KVSのように Keyでアクセスするだけ!ではないので、少し
SQLに近い側面を持っています。私はCouchBaseを少し触ったことが有りますが、
MapReduceそのものの機能をDynamoDBは持ちません。
-難しいの?
NoSQLというキーワードで切り分けるなら、
RDBが分かる人にとって比較的習得は優しいと思います。セカンダリインデックスのおかげで、
RDBに比較的近い考え方ができるからです。(もちろん
RDBの考え方に引きずられるのはあまり良くないですが。)
-RDSとどこが違う?
RDSは
RDB用のマネージドサービスという点で大きく違いますが、
VPCの中で使うのがRDSです。それに対しDynamoDBはSQSなどと同じ、パブリックサービスです。つまりオンプレや他の
クラウドサービスからDynamoDBだけを使うことが可能です。これを利用して、
スマホアプリから直接DynamoDBにアクセスしてしまうことも可能です。
駆け足で説明しましたが、上記は自分の経験上、知りたかった内容です。
とりあえず触るだけなら簡単なので、テーブルを作ってみましょう。
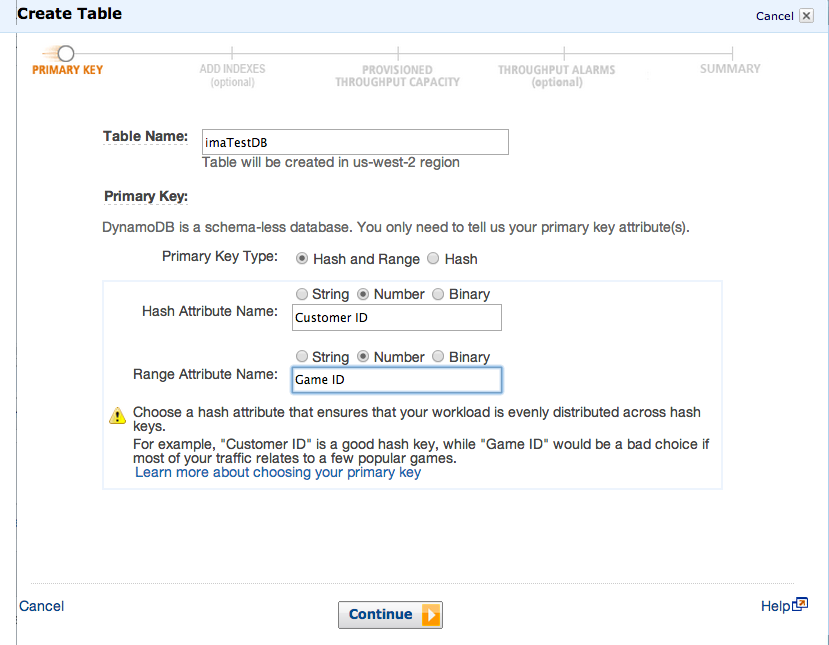
CreateTableボタンで下記画面より、テーブル名を適当に決めます。
HashとRangeの指定ですが、サンプルどおり Hashは Customer ID, Rangeは Game IDとしましょう。
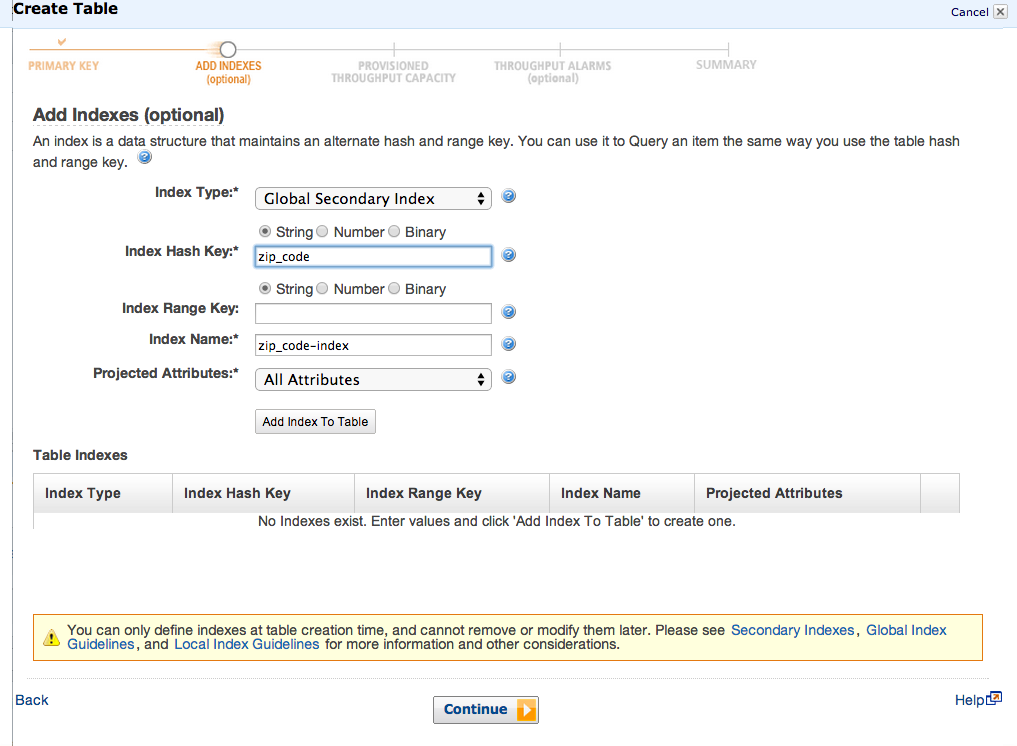
次に、グローバルとRangeを指定したので、ローカルのセカンダリインデックスの設定画面が表示されます。グローバルでzip_codeをサンプルとして指定しました。
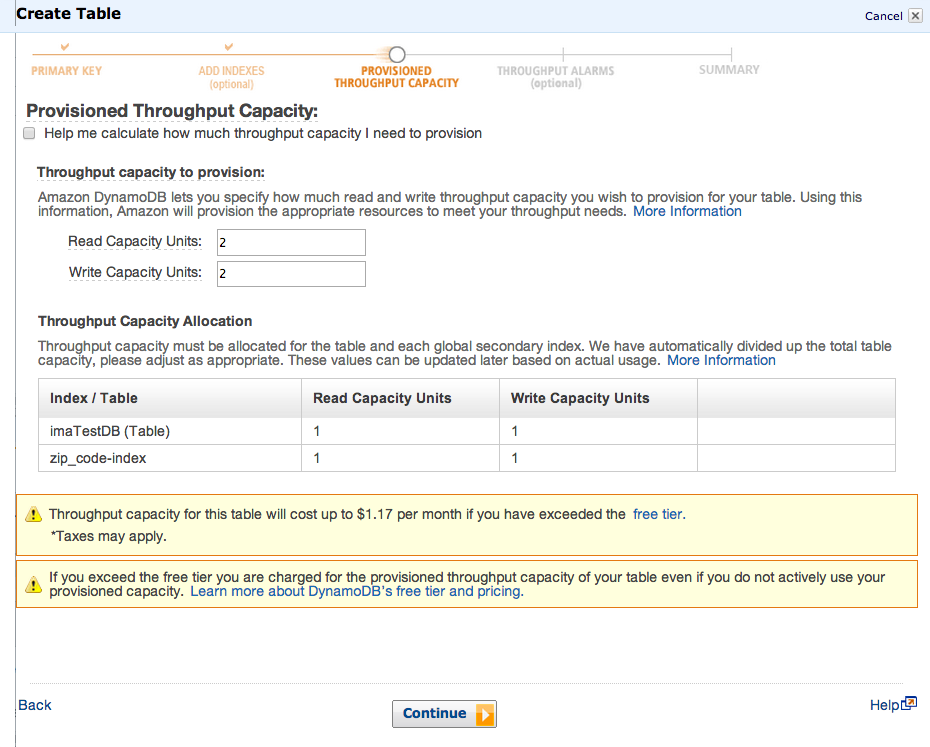
その後、パフォーマンスの設定値を決めるのですが、デフォルトのままGO
パフォーマンスが足りない時のアラームを飛ばすかと聞いてくるのですが、これはテストには不要なので、チェックを外して続行しましょう。
しばらく経つとテーブルが出来ます。
マネージメントコンソールで早速データを追加してみます。
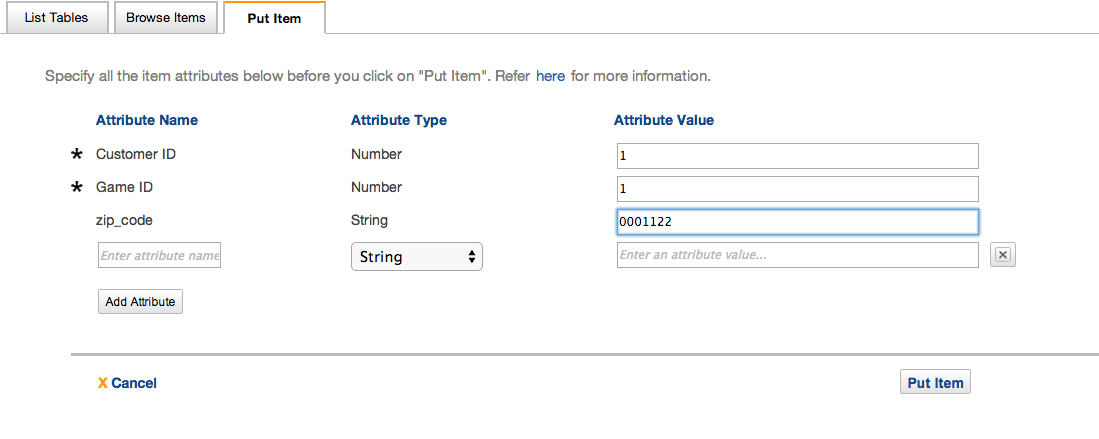
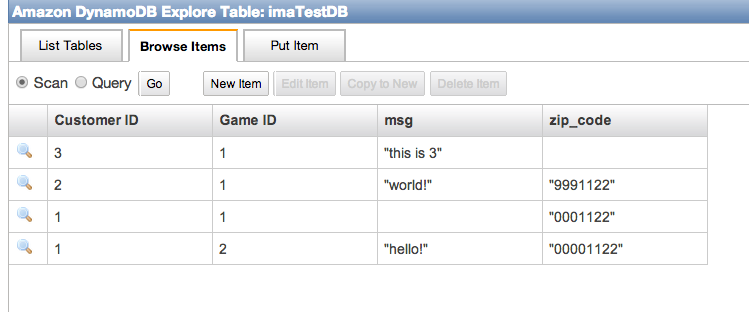
幾つか追加したデータがこれです。
注目して欲しいのは、zip_code が空のレコードがあることです。セカンダリインデックスはNullを許容されています。(というよりカラム、正確には
アトリビュートなし)この絵から、Dynamoは
RDBに近いと私も誤認していましたが、これで
スキーマレスだということが分かると思います。
後は、データの問い合わせ方法ですが、マネージメントコンソールでやっても実際コードをどうするかわからないと思うので、私の好きな
aws-
cliでつついてみます。
#テーブル一覧
$ aws dynamodb list-tables
#keyで狙い撃ち
$ aws dynamodb get-item --table-name imaTestDB --key '{"Customer ID" : {"N" : "1" } ,"Game ID" : {"N" : "1" } }'
#zip-codeで狙い撃ち
$ aws dynamodb query --table-name imaTestDB --key-conditions '{"zip_code": { "AttributeValueList": [ { "S" : "0001122" } ] , "ComparisonOperator": "EQ" } }' --index-name zip_code-index
JSONで問い合わせて
JSONで返って来ます。
プログラミング言語でやったほうが楽ですね。さらに、すぐに
APIリファレンスを読むことをオススメします。ググって楽しようと思っても無駄なことが多いとおもいます。
http://docs.aws.amazon.com/amazondynamodb/latest/APIReference/Welcome.html
DynamoDBはこれ以外にも認証や、最近発表されたオートスケール、運用面において特に
RDBの常識からこういう時はこうするというケースを取り上げていきたいと思います。NoSQLの入り口としてはとてもよいものだと思うので、
AWSのアカウント取得が少々面倒かもしれませんが、エンジニアの皆様はぜひとも使ってほしいと思いました。