
BigQuery(BQ)のスケジュールドクエリは、普通に設定すると設定したユーザー、つまり人の権限で実行されます。 これを読んでる人は何が問題かわかっているはずで、退職時にそのユーザーアカウントが消滅すると動かなくなる、だけでは済まずに設定自体が消滅します。それを避けたいのでサービスアカウント(SA)で実行したい、ただそれだけの話だけど間違った手順が広まってしまっている。
まず最初に、SAの鍵は不要です。SAでスケジュールドをやるには鍵が必須かのような認識は、今すぐ捨ててください。
参考にすべきところ
https://cloud.google.com/bigquery/docs/scheduling-queries?hl=ja#using_a_service_account
Googleの公式をしっかり読むのが結局の近道です。信頼に足る情報源としてはここが一番
コンソールから設定する
DevelopersConsole(DC)から設定する。これは時期はわからないが、比較的最近の機能のはずなので、古い記事だと直接APIを叩くしかないようにも見えますが、今は一応DCから設定はできます。
そのまえに、誰が、何をするかをちゃんと把握する
通常のスケジュールドクエリは、おおよそ下記の手順で作っているはずです。
- AさんがSQLを作成する (実際に流して結果を確認する)
- そのままスケジュールドクエリとして登録する
- スケジュールドクエリはAさんの権限で実行される
これをSAで実行する場合
- AさんがSQLを作成する
- スケジュールドクエリとして登録するときに、実行ユーザーとしてSAを指定する
- スケジュールドクエリはSAの権限で実行される
最後のスケジュールドクエリの実行はBQリソース=テーブルやデータセットに対するアクセス権限は、AさんとSAへの認可を同じものが必要。
もう一つ、SAで実行するために、スケジュールドクエリを設定するときに、SAを使う権限というものがAさんに必要となります。
また、なぜかGoogle管轄のプリセットSAに対して iam.serviceAccounts.getAccessToken が足らないとメッセージが出ることがあります。なぜ必要か説明できなし、100%発生するわけでもないです*1が、従いましょう。
- SAに対してBQリソースへの認可
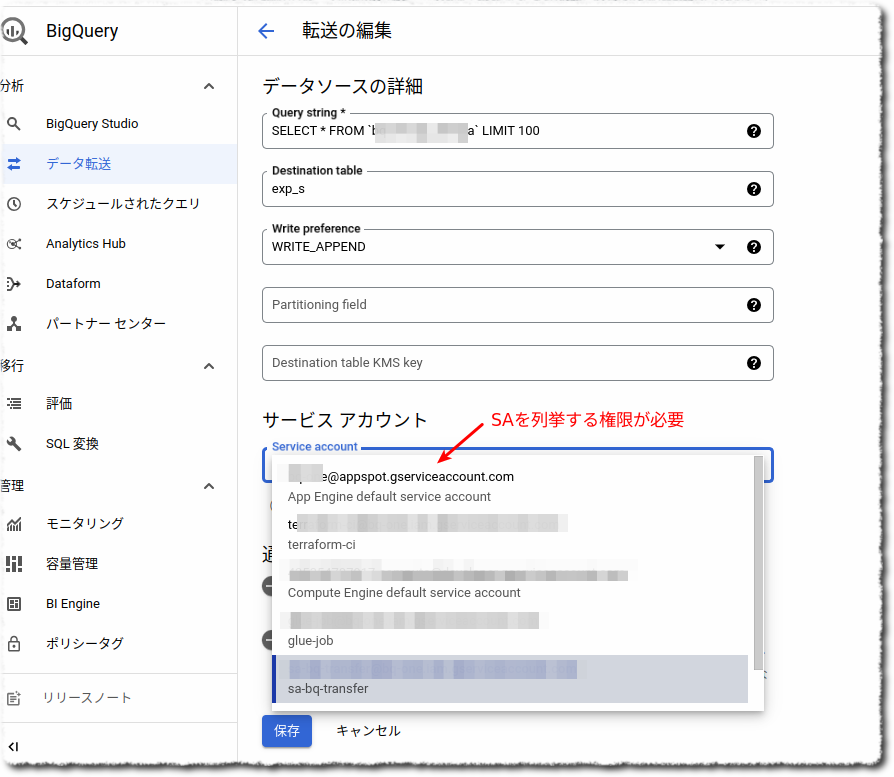
- 設定を行う人に対して 対象SAを使う認可 (Web-UIから設定したいならば、プロジェクト内のSAを列挙する認可)
- 原理は不明だが、プリセットのSAに対して
iam.serviceAccounts.getAccessToken
DCでやってみる
まず、Aさんの権限で実行してみる。参考までに下記を付与したとする。ちなみに書き込み権限は下記にはないので、調整してください。
bigquery.jobs.create bigquery.jobs.list bigquery.routines.get bigquery.routines.list bigquery.savedqueries.create bigquery.savedqueries.delete bigquery.savedqueries.get bigquery.savedqueries.list bigquery.savedqueries.update bigquery.transfers.get bigquery.datasets.get bigquery.tables.get bigquery.tables.getData bigquery.tables.list bigquery.transfers.get bigquery.transfers.update resourcemanager.projects.get
この状態でAさん自身の実行でスケジュールドクエリを定義できることを確認しておく。
次にSAを使って同じスケジュールドクエリを定義する。SAを作成して、上記Aさんと同じBQリソースに対する権限を付与する。 そこから、AさんにはSAを列挙&使う権限が存在しないため、付与する必要がある。

プロジェクトの規模にもよるが、一番安全に倒すならば、Aさんに与えるプロジェクトレベルの認可としては、SAの取得とリストのみに絞り、SAを使う認可はSA自体の権限(AWSでいうリソースポリシー)として付与するのがよい。具体的にはSAを列挙する専用ロール(SA列挙ロールと名付ける)をつくって、その中身を下記としプロジェクトでAさんに付与
iam.serviceAccounts.get iam.serviceAccounts.list
さらにSA自身の認可(このサービス アカウントにアクセスできるプリンシパル)としてAさんにServce Account User: roles/iam.serviceAccountUser のロールを付与すればOK
これでスケジュールドクエリの設定は成功する。が、設定は成功しても実行時にまれに下記のメッセージでコケることがある。
P4 service account needs iam.serviceAccounts.getAccessToken permission. Running the following command may resolve this error: gcloud iam service-accounts add-iam-policy-binding <SA-user-email> --member='serviceAccount:service-<project-id>@gcp-sa-bigquerydatatransfer.iam.gserviceaccount.com' --role='roles/iam.serviceAccountTokenCreator'
これが発生したりしなかったりで、原因はわからないが、素直に SAのポリシーに service-<project-id>@gcp-sa-bigquerydatatransfer.iam.gserviceaccount.com に対して iam.serviceAccounts.getAccessToken を付与する。
bqコマンドでやってみる
bq コマンドでやる場合ならば、SA列挙ロールは付与していなくてもOKで、SA自身の認可だけあればよい。

bq コマンドで設定する。下記はすでに定義済みのスケジュールドクエリ(転送設定)の実行ユーザーだけ差し替える方法。詳しくは公式より
https://cloud.google.com/bigquery/docs/scheduling-queries?hl=ja#bq_3
bq update \ --update_credentials \ --service_account_name=<SAのメアド> \ --transfer_config \ <スケジュールド・転送設定のリソース名>
転送設定のリソース名は
bq ls --transfer_config --transfer_location=us
とかで確認できる。ここで再度まとめておくと、AさんがSAで実行するように設定するので、AさんがSAを利用する権限が必要となる。
SA鍵を発行して、SA鍵で認証して、SA自身になりきり、SA自身をスケジュールドクエリ実行ユーザーとすることはできるが、そんなことしなくていいし、危険だから今すぐやめたほうがいい。AさんがSAを使える、もっと突っ込むと iam.serviceAccounts.actAs があればよい。で、このiam.serviceAccounts.actAs をプロジェクトレベルで振ってしまうと危ないので、SAのポリシーバインディングで付与する。
落ち穂拾い
DCから既存のスケジュールドをSA実行に切り替えたい
クエリのスケジューリング | BigQuery | Google Cloud
DCからはできないと書かれていますが、こことは別の方法でできます。BQコマンドが嫌な人はこちらで


他のプロジェクトで作ったSAで実行したい
結論から言うと、できるが、おすすめしない。
まず最初に、SAを作成したプロジェクトと、リソースがあるプロジェクトは同一である必要はない。AWSはアカウントごとに認証装置があるからこそクロスアカウントとかいう仕組みが必要だが、GCPはプロジェクト単位で認証は発生していない。だからクロスプロジェクトしていても、認可さえ与えれば問題ない。
が、SAをプロジェクト跨ぎで特定プロジェクトのリソースに縛り付ける(e.g. GCEのSAや、今回のスケジュールドクエリのSA)に使うことは、GCPのIAMによる 組織ポリシーにより禁止されている、デフォルトで。これ、組織ポリシーと名前はついているが、プロジェクトレベルでのポリシーとして動いている constraints/iam.disableCrossProjectServiceAccountUsage 、詳しく知りたい人は自分で調べてください、スクリーンショットだけ貼っておく。

ここまで読んでいる人なら大丈夫だと思うが、念の為
- SAと、スケジュールドを仕込むプロジェクトは同一
- ジョブからアクセスするBQリソース(dataset, table ...) はプロジェクトまたいでいてOK
*1:筆者の環境では一度発生すると2度目以降は不要でした。プロジェクトによってはそもそも発生しない場合もあり。











